Stanford NER Review
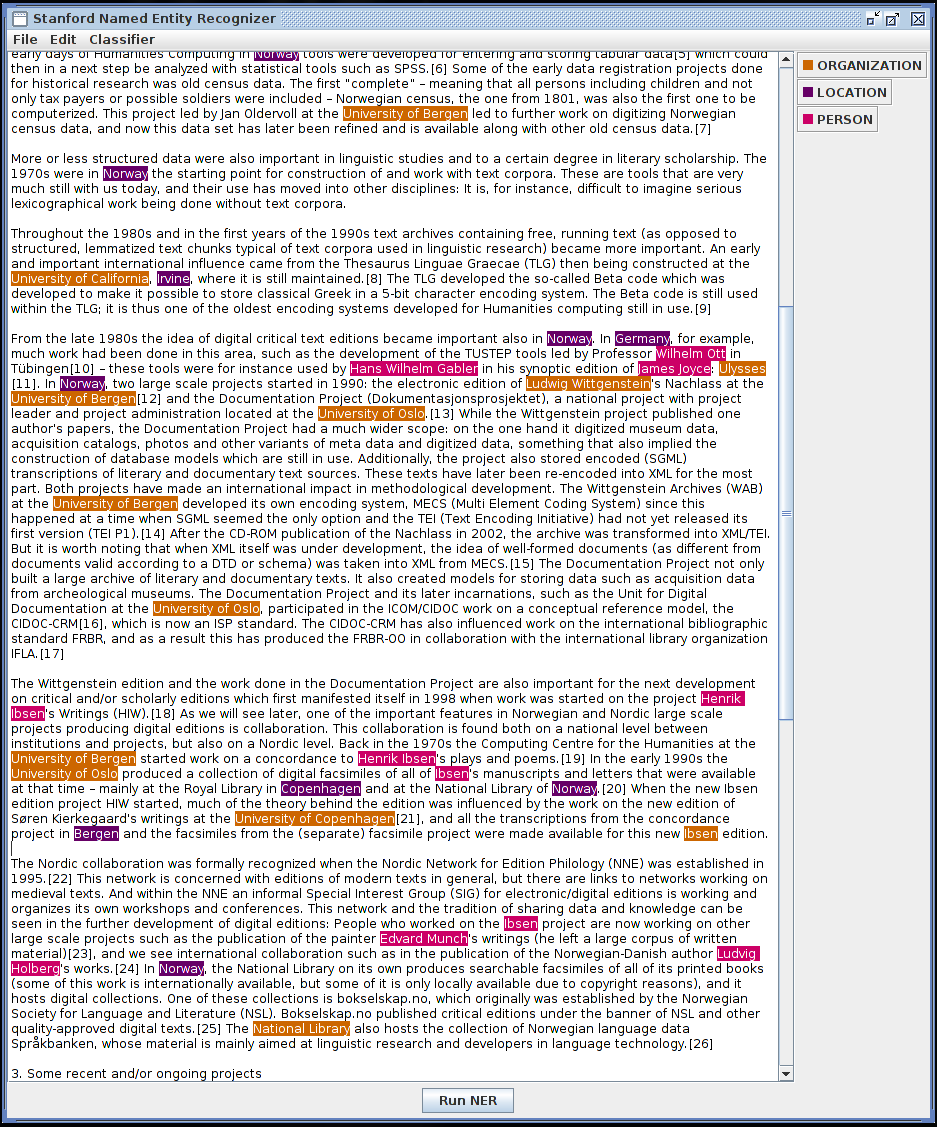 The Stanford NER demonstration GUI in action
The Stanford NER demonstration GUI in action
Overall, this software works fine. It is able to recognize most of the title-cased words in the text I chose to analyze (about DH in Norway) and correctly identify them as an Organization, Location, or Person. It did mistakenly recognize “Social Sciences” as an organization, yet correctly failed to recognize “Humanities”. I could critique the user interface but expectations are set appropriately by having to download a zip file and run the GUI with a .sh script. More interesting is the software, which I was fairly easily able to run within the Python Natural Language Toolkit, a standard for text processing. Other than having to upgrade to Java 8, this was a painless process.
As for its utility: somewhat useful. The user interface is the biggest detriment here, as I cannot increase the text size or change font, which means that it’s not very helpful for doing a full reading. But I can get a basic understanding of the organizations involved (UC Irvine, University of Oslo, University of Bergen) and some of the people (Wilhelm Ott, Hans Wilhelm Gabler) at a glance. If I were developing software with this tool, I would try to automatically link these entities to more descriptions / information about them – maybe the relevant section of a Wikipedia page, for example. It would also be fantastic from a usability standpoint if this were incorporated into a better reading tool, such as the browser on which I originally accessed the text, maybe in the form of a browser plugin.
While hyperreading the same text, it was immediately obvious that the computer could be aiding me in my work of linking this document to others. It would have also been nice if it could provide background blurbs around the different entities it recognized, much in the same way that macOS allows for the automatic definition / lookup of words:
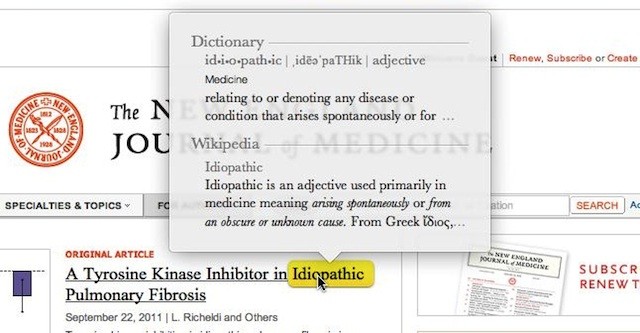
I did not find the NER particularly useful for close reading of a single document, but if it were to enable links between multiple related documents (say, in a single corpus) I would find it nice to be able to jump to related ideas or references in all of the documents in the corpus any time they’re mentioned.