Text Mining Exercise - Will
I experimented with looking at my personal canon for the text mining exercise, as I was curious if I would be able to note any common overlap between the common phrases that I use I use in my writing across a number of years. To begin, I compiled all of the essays and response papers from my Junior year of high school, and pasted all of them into a single text file, which I then entered into Voyant.
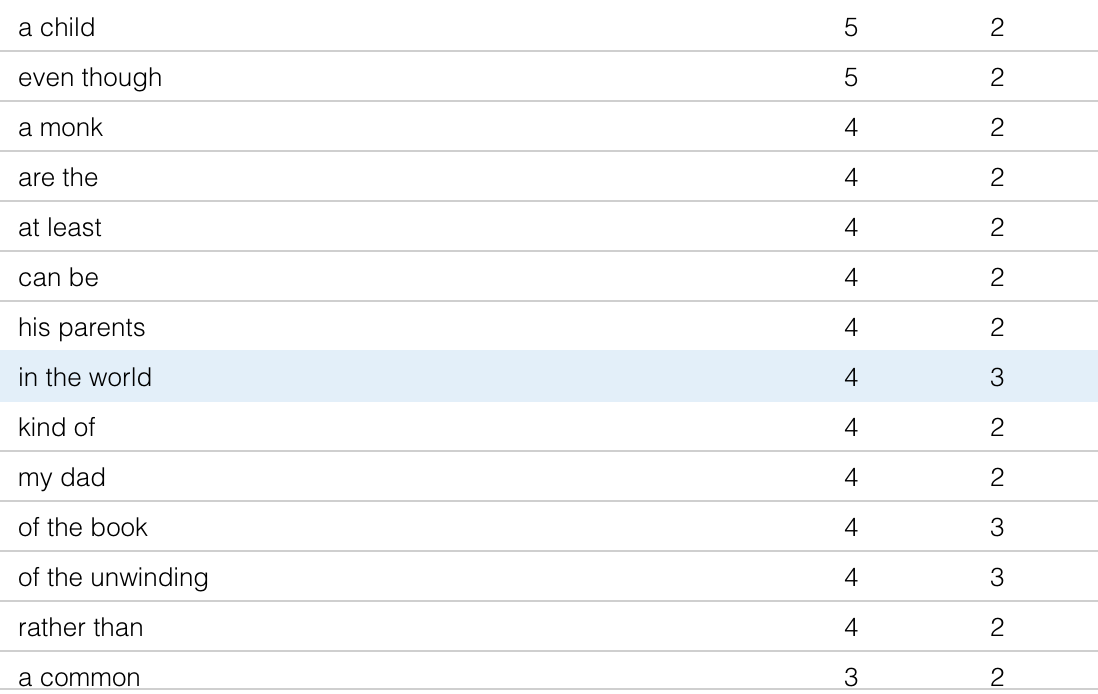
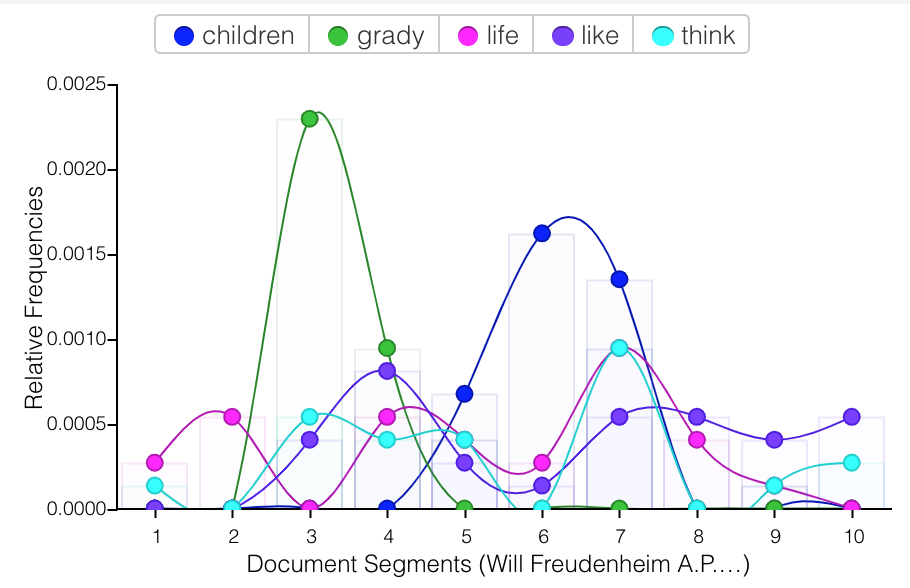
The results looked like this. There are clearly some words that I use in specific response papers that end up popping up enough to overtake the common phrases throughout my writing. With more texts these results would be smoothed out. I do say a horrifying amount of “even though” and “kind of” at this point, which I would have hoped might have been ironed out of my writing by that point! You can see in the chart how certain words like “children” and “grady” have quite high peaks, because they are the related to an essay topic from that area of the total corpus from this era.
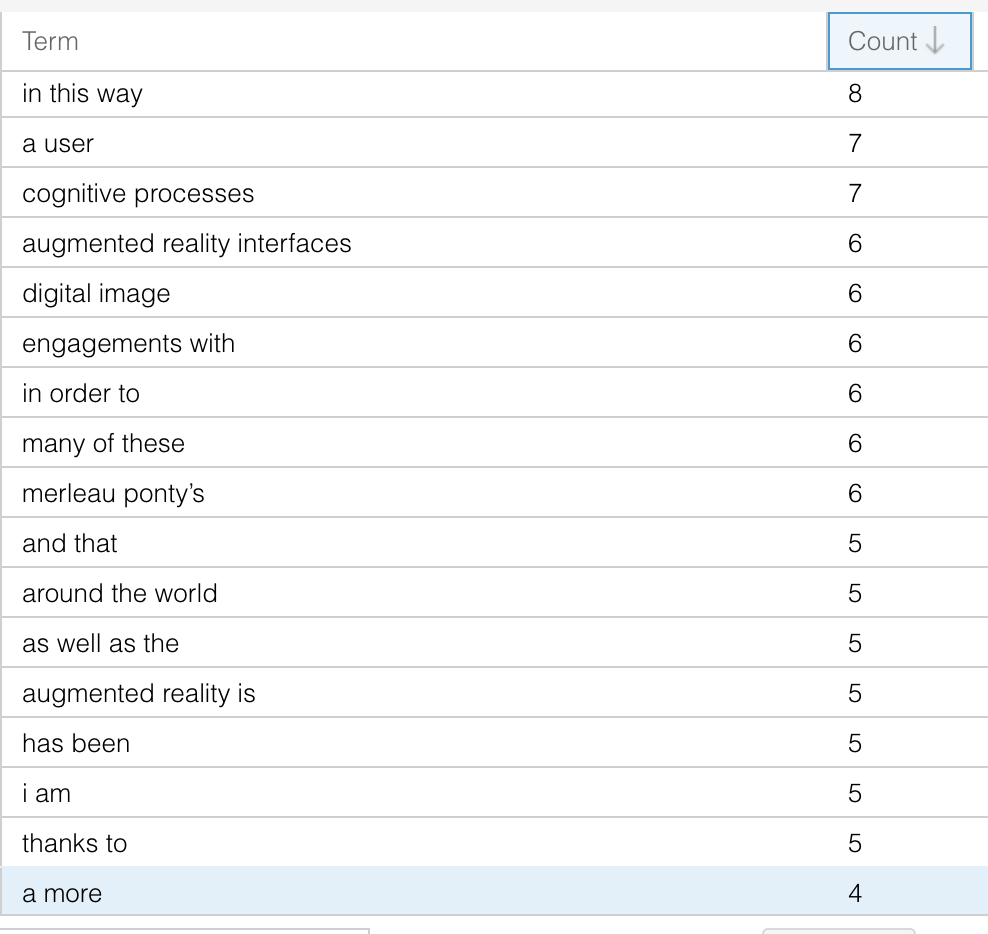
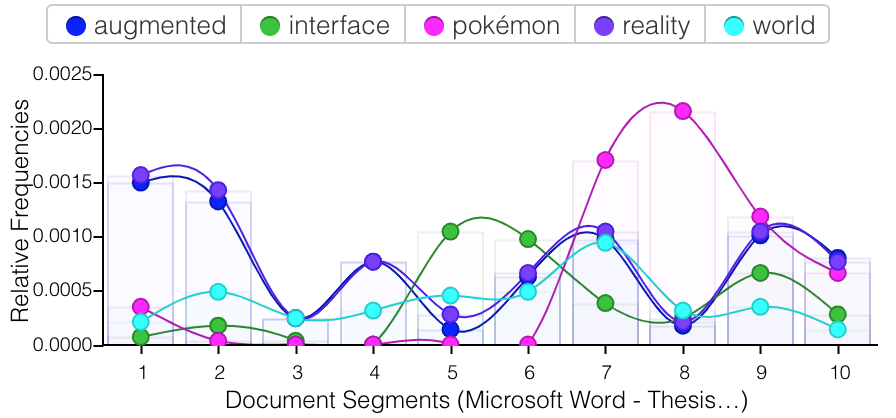
I compared these writings to my college thesis, which was a much longer single file that I could drop right into Voyant. Similarly, the specificity of the subject led to certain unique phrases appearing at a far higher rate than they would across my imagined full corpus of this time. However, there were more general phrases that I use repeatedly that do not appear in my older writings, the main ones being “in this way,” “engagements with,” and “in order to”. Given the examples of my top five words (augmented, interface, pokémon, reality, and world) this sample does not feel representative of my general writing style of this moment, even though it is the majority of writing that I have from the time.
For future projects of this kind it would be quite interesting to do this style of text mining on the entirety of someone’s text messages, or to split a person’s messages into time periods of their life or by who they are speaking to. I often wonder how the way that I communicate over text has changed over time, and how much that is a circumstance of my own language changing, or where I am living and who I am surrounded by. Relatedly, I wonder how much these changes in place and time affect my language over-all or if I still have very specific patterns of communicating with certain people, like the friends that I’ve been texting with since I first had a phone. I think tools like Voyant are useful in answering these preliminary questions, though I think they would be far more valuable if you could more clearly specify examining changes over time. The graph area attempts this by looking at word usage through “document segments,” (I am not completely sure what this means) but it would be useful to be able to more granularly study these changes over time via groups of texts.